Tapani Honkanen
This article is the first one in a series of articles that deal with the topic of interpretable machine learning. The use of artificial intelligence is increasing rapidly within the industry. A recent survey by Silo AI (2022) found that 73 % of Nordic companies who answered use artificial intelligence as a key part of their product or service. As the application of artificial intelligence, and machine learning as its subfield, increases it also becomes ever more important to consider the sustainability aspects of this technology. The promotion of interpretable artificial intelligence contributes especially to the societal sustainability of this technology.
What are Machine Learning Models?
Machine learning has a variety of practical applications today. It is often used where it would otherwise be hard, or even impossible, to solve a problem with other available methods and tools. Facial recognition, which as a technology can nowadays be found almost everywhere, is one such application area. As explained by Klosowski (2020), this particular area has seen many controversial developments over the years as law enforcement officials and other authorities have started to use this technology. Other very common application areas for machine learning are different image and speech recognition tasks, malware detection, credit risk assessment, surveillance, and healthcare.
A machine learning model can simply be thought of as a computer file that has been generated as a result of a model training process. During model training, patterns are extracted from the training data with the help of algorithms (Radich et al., 2021). Trained models, which meet certain predefined business requirements, can then be used for making predictions from new data in different production environments. This process of making predictions is also called inference.
Machine learning solution development typically requires involvement from several different experts and stakeholders within a company, and the development process itself can be quite complex to manage. Amershi et al. (2019) present the major stages of the typical development and productization workflow. The actual machine learning model is an output from the model training and evaluation phases. The model itself can be deployed to either a device as part of a software package, or to a cloud service for consumption through an application programming interface (API).

Interpretability of Machine Learning Models
Let’s consider a short example before defining interpretability more closely.
Company A has developed and trained a machine learning model to predict credit worthiness of customers during an online loan approval process that is routinely handled at the company. For this, they use a wide range of different types of features ranging from income to habitation status that the customer provides during a submission of a loan application. The model they’ve developed seems to initially perform exceptionally on metrics that measure the predictive performance of the model, even when deployed to production. After a little while, complaints start coming in that a particular group of customers are not being given loans, even if a closer inspection reveals that they should be eligible for this. Through a long bout of detective work, it is found that these customers, who also mostly are part of an ethnic minority, were living in poor neighbourhoods. Features pertaining to habitation status were found to be highly correlated with a prediction result, and some people were wrongly classified because of this. Although this is a highly simplified example, it highlights the fact that because of a false prediction result, the productionized model treats a specific group of customers in a manner that is not desirable! It is easy to understand how this could hurt the business and its trustworthiness.
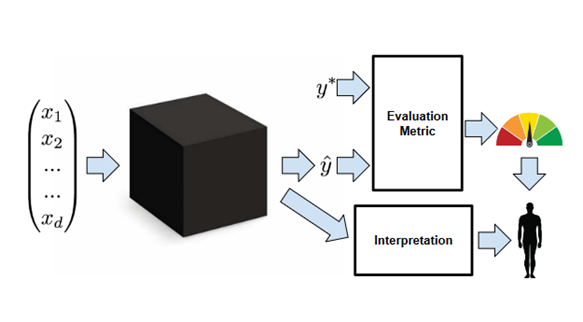
As such, the concept of trust in machine learning models is a central idea when thinking about the need for model interpretability. Doshi-Velez et al. (2017) imply that interpretability is needed to confirm that important quality criteria for machine learning systems are being met. For example, it is vital to ensure that the model does not discriminate against protected groups of people when providing inference. That is, the system performs in a fair and unbiased manner. Similarly, in other cases, it might be important to verify that a production system performs reliably even if prediction inputs provided to it fluctuate. Interpretability is needed to verify the reliability and robustness of the system in this case.
Interpretability has been defined by Miller (2018) as “the degree to which an observer can understand the cause of a decision”. Interpretability based on this definition is used as a means for obtaining an understanding of how a model generates its predictions. In many cases, it is also equally important to justify a particular prediction result. It is worth noting that how well we can interpret a model is also dependent on our own cognitive abilities as humans – we have limited capacity to inspect complex models.
According to Lipton (2017), interpretability can be approached through the concept of model transparency and our ability to extract information from a learned model (so-called post-hoc interpretability). In a manner, we could state that simpler machine learning algorithms typically are also more transparent, and hence more easily interpretable. This of course is not completely true, as there are factors which can make even simpler models more complicated to interpret. Such situations can arise, for example, from model parameters and the complexity of training data.
Lipton (2017) defines transparency, or model intrinsic interpretability, as dependent on factors such as:
- the size of the model,
- the possibility of finding intuitive explanations for the different parts of the model,
- the ease of creating visual representations of the model which the user can easily inspect, and
- level of trust in the fact that the algorithm used always behaves as is expected.
Once we have a trained model, post-hoc tools such as automated model explanations and different types of visualization methods can be applied to provide further information on how the model is arriving at its results.
When is it beneficial to assess model interpretability?
It should be noted that interpretability is not a factor which has to be considered during all machine learning projects. When assessing the need for interpretability, in the opinion of the author it can be beneficial to ask the following questions:
- Is there a need to consider minority groups in terms of prediction results?
- Could the model predictions affect people in some other manner that might be harmful to them?
- Is data privacy a consideration? What about other local, regional, or domain-specific legislation?
- Is there a chance that the prediction results will cause any negative business impacts? If yes, what would be the estimated impact of these?
- Is the solution to be developed a novel one, or has it been implemented routinely by others?
- Will trust factors pose an issue, even if there is not a strict need for increasing interpretability? Will it be crucial for adoption?
- Is there a chance that developing a more interpretable model allows for misuse?
The above list of questions is not a complete one but does give a good starting point for considering the need for interpretability during a machine learning project. Ideally, these questions are answered during the project scoping and the following model requirements phase before proceeding to other more technically involved data science phases such as data collection, feature engineering and modelling. Many of the interpretability-related challenges can be addressed best during the early phases of the project.
This short article has provided a concise introduction to the subject of model interpretability. Within the next articles, we will dive deeper into the current state of this topic.
Author
Tapani Honkanen, Head of Degree, Business Information Technology & Computer Applications, HAMK Häme University of Applied Sciences.
References
Amershi, S., Begel, A., Bird, C., DeLine, R., Gall, H., Kamar, E., Nagappan, N., Nushi, B., & Zimmermann, T. (2019). Software Engineering for Machine Learning: A Case Study. 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), 291–300. https://doi.org/10.1109/ICSE-SEIP.2019.00042
Doshi-Velez, F., & Kim, B. (2017). Towards A Rigorous Science of Interpretable Machine Learning (arXiv:1702.08608). arXiv. http://arxiv.org/abs/1702.08608
Klosowski, T. (2020, July 15). Facial Recognition Is Everywhere. Here’s What We Can Do About It. Facial Recognition Is Everywhere. Here’s What We Can Do About It. https://www.nytimes.com/wirecutter/blog/how-facial-recognition-works/
Lipton, Z. C. (2017). The Mythos of Model Interpretability (arXiv:1606.03490). arXiv. http://arxiv.org/abs/1606.03490
Miller, T. (2018). Explanation in Artificial Intelligence: Insights from the Social Sciences (arXiv:1706.07269). arXiv. http://arxiv.org/abs/1706.07269
Radich, Q., Jenks, A., & Cowley, E. (2021, December 30). What is a machine learning model? What Is a Machine Learning Model? https://learn.microsoft.com/en-us/windows/ai/windows-ml/what-is-a-machine-learning-model
Silo AI. (2022). Silo AI: Nordic State of AI 2022.